

하염! Brighics 서포터즈 3기 수망입니다!
저.. 오랜만에 개인 프로젝트 했더니 정말 탈탈 털리고 있어요 ㅎㅎ...
공부는 해도해도 끝이 없다는 말을 실감하는 요즘이에요 핳
그치만!!! 새로운걸 배우는건 언제나 조금은(ㅎ) 재밌지 않..나요?!
ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ
오늘 내용 아주 ... 알차요......ㅋㅋㅋㅋㅋ
(그만큼 힘들었다는 뜻ㅎ)
그럼 오늘 포스팅도 바로 시작해볼게용

먼저, 스피어만 방식으로 상관관계가 구해진 그래프를 이용해 해석한 이유는
각 변수들이 정규성을 만족하지 않기 때문이에요!
(Profile Table 결과창을 보면 skewed로 출력된 변수가 있을텐데요,
이건 해당 변수가 비대칭이라는 것을 의미합니다! 즉 비정규성을 띈다는 의미죠)

평균 신용+체크카드의 이용금액 합계는
평균 체크카드 이용금액, 평균 해외 이용금액와의 상관관계가 높게 나타났지만
신용+체크카드의 이용금액 합계/이용인구수, 체크카드 이용금액 합계/이용인구수,
해외 이용금액 합계/이용인구수 와의 상관관계는 낮은 것으로 나타났어요.
- Statistic Summary & String Summary

statistic summary로 결측인 셀을 count해보았습니다!
결과를 보면 이용 금액과 인구수 부분에서 결측치를 발견할 수 있었습니당ㅎㅎ
그리고 String Summary로 문자열(string) 값들로 구성된 '시군구명'의 컬럼을 요약한 결과,
max는 '중구', min은 '강화군', 최빈값은 '전체', unique 값의 갯수는 11개인 것을 알 수 있었습니다.
4. 결측치 처리(Replace Missing Value)
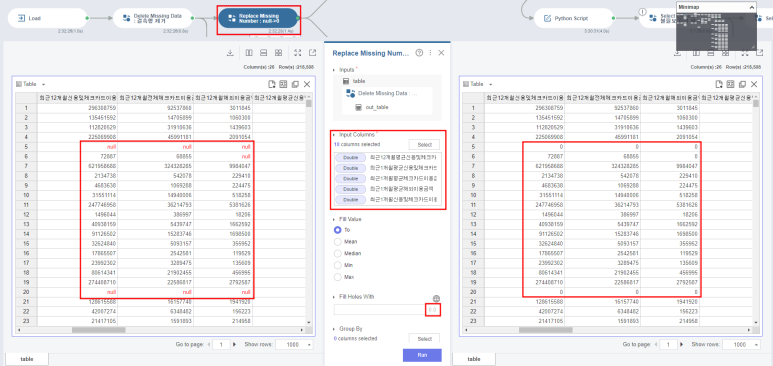
Statistic Summary에서 살펴본 것처럼 작업 전의 데이터셋을 보면 결측인 셀들을 볼 수 있는데,
이 데이터는 합계, 고객수, 평균으로 이루어져있기 때문에 다른 컬럼과 비교해보면서
0은 모두 빈칸으로 처리되었구나!! 라고 금방 발견할 수 있었어요.
그래서 결측으로 입력된 셀은 모두 0으로 처리했습니다.
5. EDA(1)
EDA를 시작하기에 앞서, 정확한 y지표 선정이 필요했고
저는 '최근 1개월 평균 신용 및 체크카드 이용금액'으로 선정했습니다.
그리고 pivot 블럭을 사용해서 row에 목적에 맞는 입력변수를 넣고
values에는 1개월평균신용및체크카드 이용금액을, 함수는 mean으로 입력하여 실행한 뒤 시각해보았습니다.
- 분위별 소비금액 평균 & 행정구별 소비금액 평균 (단위 : 천원)

row에 각각 분위구분과 시군구명을 넣은 column 그래프를 나타내보았는데용
분위구분에서는 '전체'를 나타내는 0분위에서는 소비금액 평균이 약 150만원이라고 하고,
전반적으로 1분위부터 10분위까지 소비금액이 증가하는 추세였습니당
시군구명에서는 웅진군의 소비금액이 100-110만원대로 가장 적고,
연수구의 소비금액이 150만원 이상으로 가장 크다는 것을 파악할 수 있었습니다
- 성별에 따른 분위별 소비금액 평균 & 행정구별 소비금액 평균 (단위 : 천원)

row에 각각 성별을 추가해 color by에 성별을 더한 column 그래프를 나타내보았는데요!
분위 구분에서는 분위에 상관없이 남자(1)와 여자(2)의 소비금액 평균이 비슷하며
분위가 증가함에 따라 소비금액이 증가한다는 결과를 얻었습니다!
시군구명 시각화 결과로는 인천광역시의 행정구별 소비금액 평균이
대체적으로 남녀 모두 150만원선이라는 점을 알 수 있었습니다.
그리고 여기서 잠깐!!!! 저 데이터 하나만 더 쓸게요 ㅎ
사실 이제 이상치를 살펴보고 처리할 차례인데요 ㅎㅎ
문제가 생겨버렸거든요..ㅎ
'소비'로 얼마를 사용하는지는 알겠어!!
근데, 얼마를 버는데??
이걸 모르는거예요..ㅠㅠ
1. 소득 데이터 추가
그래서 저는 같은 기관에서 제공하는 인천광역시의 소득 데이터에서 '평균소득'만 추가로 이용하기로 했습니다!
인천광역시_소득 데이터_20200630 | 공공데이터포털 (data.go.kr)
인천광역시_소득 데이터_20200630
인천광역시 행정구별 소득데이터로 성별/10세단위 연령별/직업별/소득분위별 금융데이터 입니다.(기준년월 : '16.12.~'20.06.)<br/>* 성별 [0 : 전체, 1 : 남성, 2 : 여성] <br/>* 직업구분 [0: 전체, 1:자영업
www.data.go.kr

소득 데이터의 컬럼은 이렇게 이루어져있는데 저는 '평균소득' 한개만 쓰겠습니당
2. 소득 데이터 전처리(1)

데이터를 다운받아 part1의 포스팅과
같은 과정의 작업으로 파일을 합쳤습니다.
아 그리고 데이터 소개란에서 소비데이터랑 다르게
소득데이터는 단위가 만원이라고 써있는데요.
소비데이터의 단위인 '천 원' 보다는 '만 원' 단위가 해석하기에 편리할 것 같아서
소비데이터에 Python Script로 금액 단위를 만원으로 변경했습니다!
(이 부분은 소비데이터 전처리 입니다)

소비데이터 전처리 과정은 이렇게 했어요!!
내용이 길어질거같아서 그림 하나로 정리한돠.
(발로 쓴 글씨 같지만.... 이해해주시길........미안)
다시 소득 데이터로 돌아와서~!

Delete Missing Data로 '행정동코드' 컬럼을 입력해 결측행을 제거하고
Select Column으로 [기준년월~평균소득]까지 선택한 뒤,
Replace Missing Number로 평균소득이 null로 입력된 부분을 0으로 대체해주었습니당
그리고 '평균소득'은 NICE 연소득 추정금액의 평균(=연봉)이기 때문에 1개월 단위로 나누는 작업이 필요해요!
이 작업은 Python Script 블록으로 해주었습니다

3. EDA(2)
그럼 이제 소비 데이터와 같은 방식인 'pivot 블럭'으로 분위별/행정구별 평균소득의 평균..(?) 말이 이상하네요 ㅋㅋㅋㅋㅋ
평균소득의 mean으로 칭할게요!
pivot 블럭을 사용해서 row에 목적에 맞는 입력변수를 넣고
values에는 평균소득을, 함수는 mean으로 입력하여 실행한 뒤 시각해보겠습니당
- 분위별 평균소득의 mean & 행정구별 평균소득의 mean (단위 : 만원)
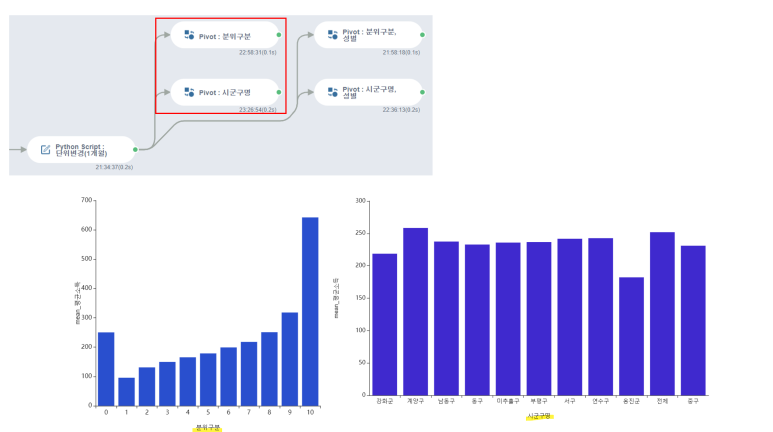
row에 각각 분위구분과 시군구명을 넣은 column 그래프를 나타내보았는데용
분위구분에서는 '전체'를 나타내는 0분위에서는 1개월 평균소득이 약 250만원으로 나타났고 ,
1분위부터 10분위까지 소비금액이 증가하는 추세임을 발견했습니다!
(10분위 평균소득 700만원 우오아우.. 지져스)
그리고 시군구명에서는 웅진군의 평균소득이 200만원 미만으로 가장 적고,
계양구의 평균소득이 150만원 이상으로 가장 크다는 것을 파악할 수 있었습니다!!
- 성별에 따른 분위별 평균소득의 mean & 행정구별 평균소득의 mean (단위 : 만원)

row에 각각 성별을 추가해 color by에 성별을 더한 column 그래프를 나타내보았는데요!
분위 구분에서는 분위에 상관없이 남자(1)와 여자(2)의 평균 소득이 비슷하지만
몇몇 분위에서는 남성의 소득이 더 많은 것으로 나타났습니다.
시군구명 시각화 결과로는 강화군의 여성 평균 소득이 200만원 미만,
웅진군의 여성 평균 소득이 약 150만원으로 나타났습니다!
6. 두 데이터 결합(Join)
이제 소비와 소득 데이터를 결합 해줄텐데요.

Join Type : inner, Left/Right Keys : [기준년월, 행정동코드, 시도명, 시군구명, 성별, 연령별, 직업구분, 분위구분]를
입력한 뒤 실행합니다.

그럼 이렇게 마지막 열에 평균소득이 추가 되어있을거에요!!
7. 이상치 제거
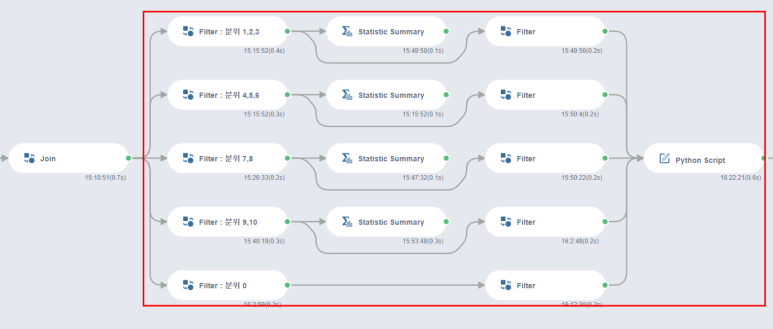
두둥,, 드디어 합쳐놓은 데이터를 다시 나누게 됩니다..ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ^^
견...뎌....ㅋㅋㅋㅋㅋㅋㅋ
그리고 이 과정은 이렇게 좀 길어요...ㅎㅎ
그래서 1,2,3 분위랑 9,10 분위만 설명해보도록 할게요ㅋㅋㅋ
먼저 첫번째로 소득이 있는 사람 중
그 소득이 90만원~200만원 사이인 1, 2, 3분위를 대상으로 소비금액 이상치를 제거해볼게요!

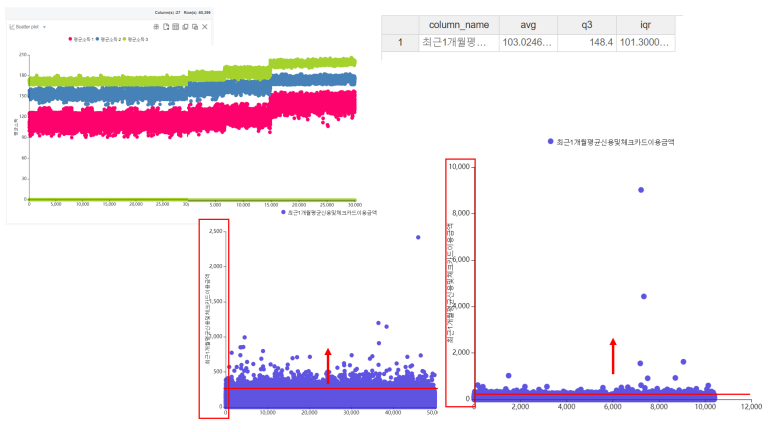
Filter 블록으로 분위구분이 1,2,3인 분위수를 추출한 뒤 소비금액을 살펴봤습니다.
소득의 최대값은 195만원이었고 소비하는 금액의 평균은 103만원이었지만,
그 이상을 소비하는 데이터도 적지 않게 볼 수 있었어요!
그리고 전 300(Q3+1.5*IQR)만원을 이상치 기준으로 선정해
Filter 함수로 300만원보다 많이 소비한 데이터를 제거했습니당
여기서!
"어? 과소비 너무 심한데..?" "이상치 기준이 너무 높은데" 라고 생각하셨을 수도 있을 것 같아요
이상치 기준이 소득 최대금액보다 큰데도 이렇게 선정한 이유는 다음 그래프를 한번만 봐주십셔
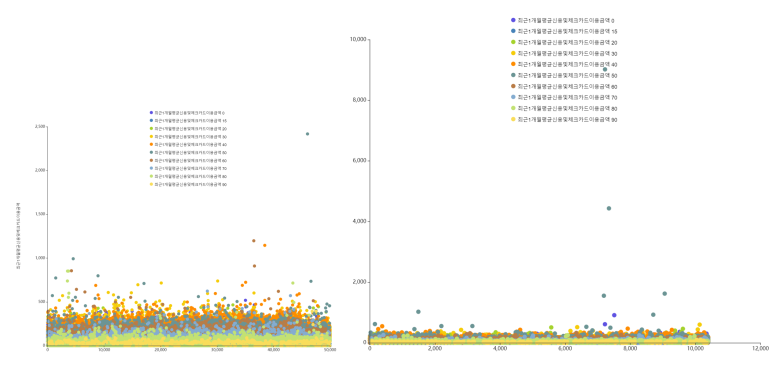
자 이건 연령대별 소비금액을 나타낸건데요!
4-80대의 소비가 많은 것으로 보아, 배우자와 맞벌이를 하거나
자녀가 주는 용돈을 사용할 수도 있고 모아둔 돈을 사용했을 수도 있을 거라고 생각했어요.
이 외에도 여러 변수를 고려했을 때, 소득 금액보다 소비 금액이 클 수도 있다고 판단하여
소득 금액과 소비 금액간 간격이 너무 큰 데이터만 제거하기로 했습니다. (다른 분위에서도요)
그리고 이 때 outlier dection 함수 사용하면 되는거 아니냐는 질문할 수도 있는데,
저는 소비가 0원인 데이터를 살려두기 위해서 filter 함수를 사용해서 이상치를 제거했습니당!
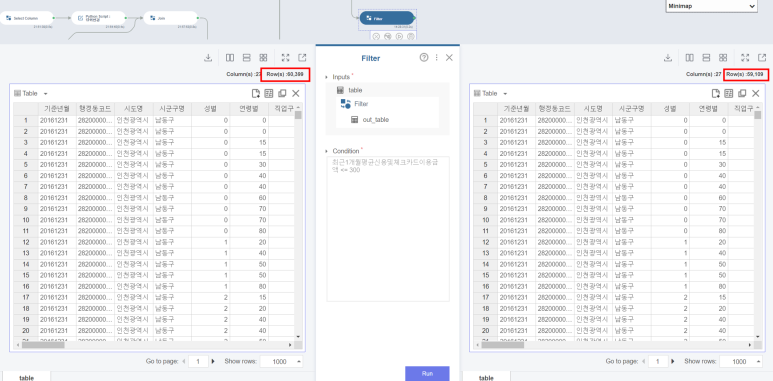
60,399개의 행이 59,109개의 행으로 줄어들었죵??
이번에도 똑같이 소득이 있는 사람 중
그 소득이 311만원~1억 6000만원 사이인 9~10분위를 대상으로 소비금액 이상치를 제거해보겠습니당
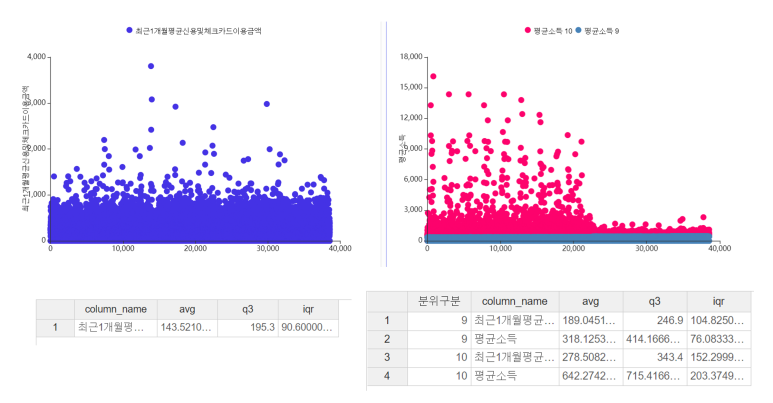
Filter 블록으로 분위구분이 9,10인 분위수를 추출한 뒤 소비금액을 살펴보았는데여
두 분위를 묶어서 살펴보았을 때의 소득은 최대 1억 6천만원, 평균은 477만원이었고
소비하는 금액의 최대는 3800만원, 평균은 233만원이었습니다,
그리고 분위별로 살펴보았을 때는 10분위의 최대 사용금액은 2980만원, 평균 사용금액은 189만원이었고
9분위의 최대 사용금액은 3803만원, 평균 사용금액은 278만원이었습니다!
해당 분위에서는 소비 금액의 범주도 넓지만 소득 금액의 범주도 함께 넓기 때문에
소득 데이터의 이상치 제거도 같이 진행했습니다!

소비는 두 분위 전체를 대상으로 계산한 330(Q3+1.5*IQR)만원을 이상치 기준으로 선정해
330만원보다 많이 소비한 데이터를 제거했구요.
소득은 10분위를 대상으로 계산한 1020(Q3+1.5*IQR)만원을 이상치 기준으로 선정해
평균소득이 1020만원보다 큰 데이터를 제거했습니다.

우오아아아 길었다!
그럼 오늘 분량 끝~!~~!
이상치 제거 후 결합하는 부분부터는 다음 포스팅에 쓰도록 할게요!
하... 하얗게 불태웠어..
쓰고 보니 왜 별로 없는 것 같죠..?ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ
저는 지금 몇번째 갈아엎고 하는건지 모르겠숴열~..
....ㅇ<-<...
아 팀원들 보고 싶다

이번주에 모델링 작업 전까지 전처리 작업을 끝내려고 했는데,
갑자기 데이터 하나가 하염! 하면서 들어와버리고
분량이 폭💛발💛 내 머리도 폭💛발💛해버렸어요 ㅋㅋㅋㅋ
아쉽게도(?) 분량.. 조절 실패..
그래서 다음주에 이어집니다 하하하ㅏ
다음주에도 전처리만 할 수...도 있지만!!!!
그럼 다음주에 봐용
끝!
본 포스팅은 삼성SDS Brightics 서포터즈 3기 활동의 일환으로 작성하였습니다.
#삼성 #삼성SDS #브라이틱스 #브라이틱스서포터즈 #서포터즈 #분석플랫폼 #분석프로그램 #데이터분석 #빅데이터 #인공지능 #분석가 #모델링 #통계 #빅데이터분석 #데이터사이언스 #파이썬 #대학생 #대학생대외활동 #대외활동 #분석툴 #AI #python #R #brighticsAI #brightics
'Brightics' 카테고리의 다른 글
| [삼성 SDS Brightics] #6_개인프젝 :: 인천인 소비금액 예측_part3. 이번주부터 모델링? 어림도 없지 (0) | 2022.10.23 |
|---|---|
| [삼성 SDS Brightics] #6_개인프젝 :: 인천인 소비금액 예측_part4. 모델링 드갑니다(1) (0) | 2022.10.23 |
| [삼성 SDS Brightics] #6_개인프젝 :: 인천인 소비금액 예측_part1.소개&전처리 (1) | 2022.10.04 |
| [삼성 SDS Brightics] #5_팀 영상 제작 일지🎥 _③ 여러분의 컨펌은 유튜브로 모시겠습니다?! (0) | 2022.09.27 |
| [삼성 SDS Brightics] #5_팀 영상 제작 일지🎥 _②. 연기와 현타, 그 사이 어딘가.... (1) | 2022.09.19 |