

하염!
Brighics 서포터즈 3기 수망입니다!
흑흑흑규ㅠㅠㅠㅠ 방금 다 쓴 포스팅을 날렸어요.. 울고 싶어요...
하지만 저는 쓸 겁니다.
왜냐면 오늘은 Credit Card Approval Prediction 프로젝트의
마지막 편을 진행하는 날이기 때문이죳!!!

(브라이틱스로 분석해본 첫 프로젝트인데다가)
(3주에 걸쳐 마무리한거라 갱쟝히 신남)
오늘 수행할 Step들과 플로우를 살펴보고 시작해볼게요!
오늘의 goal :
1. STATUS = 1(승인거부)의 데이터를 Over-sampling
2. Random Forest Classification Train (all feature /part feature)
3. Random Forest Classification Predict
4. 성능평가

본격적인 STEP1에 들어서기에 앞서,
멘토님의 코멘트와 Brightics Studio 튜토리얼을 참고한
불균형 데이터 샘플링 방법 3가지에 대해 소개할게요! (원래 4개 있습니다..ㅎㅎ)
|
방법
|
특징
|
|
Under Sampling
(Cluster Centroids)
|
|
|
Over Sampling
(SMOTE)
|
|
|
Random Sampling
|
|
https://www.brightics.ai/kr/docs/ai/manual/tutorial/b19f13b94cc87c33.html#65e83b878bc44ea5
Brightics Studio 1.1 Tutorial
www.brightics.ai
STEP1. STATUS = 1(승인거부)의 데이터를 Over-sampling
저번에 전처리해둔 파일 두개를 다시 살펴볼게요!
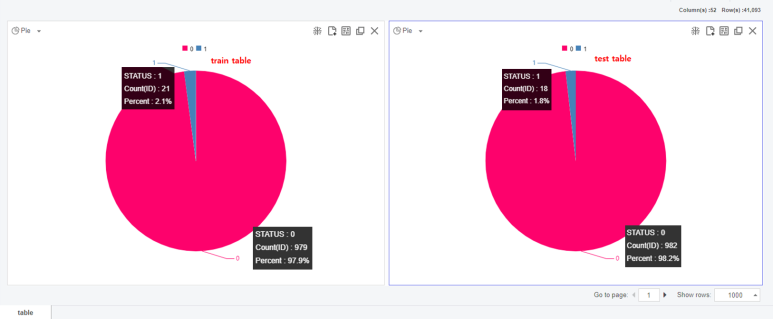
이렇게 타겟 클래스의 불균형이 심한 데이터로 모델 학습을 한다면
그 모델은 한쪽으로 치우친 결과를 내릴 수 밖에 없게 되겠죠?!
그래서 저는 99:1의 어마무시했던 데이터 차이에서,
라벨이 1인 데이터들을 99만큼 키워줄건데요,
앞서 소개한 세가지 방법 중 오버 샘플링을 사용해서 진행해보겠습니당!
- 라벨이 1인 데이터를 over sampling _Over Sampling(SMOTE) 사용
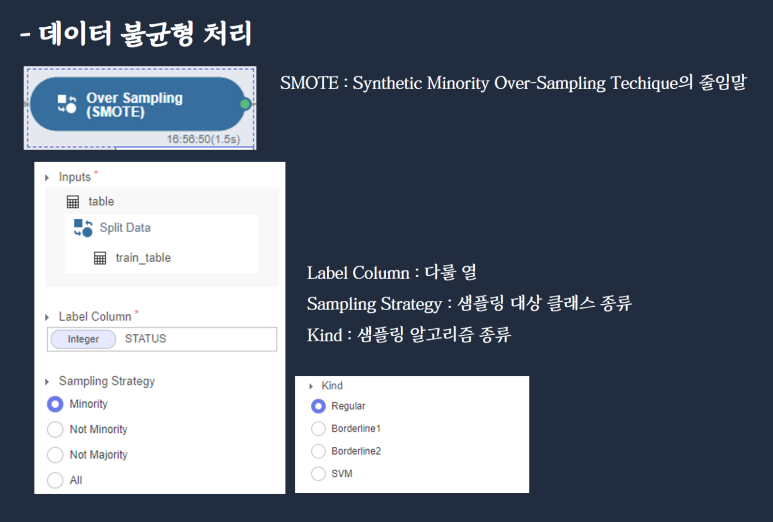
Over Sampling(SMOTE) 함수를 이용하여 라벨이 1인 소수 데이터를 오버 샘플링해줄게요.
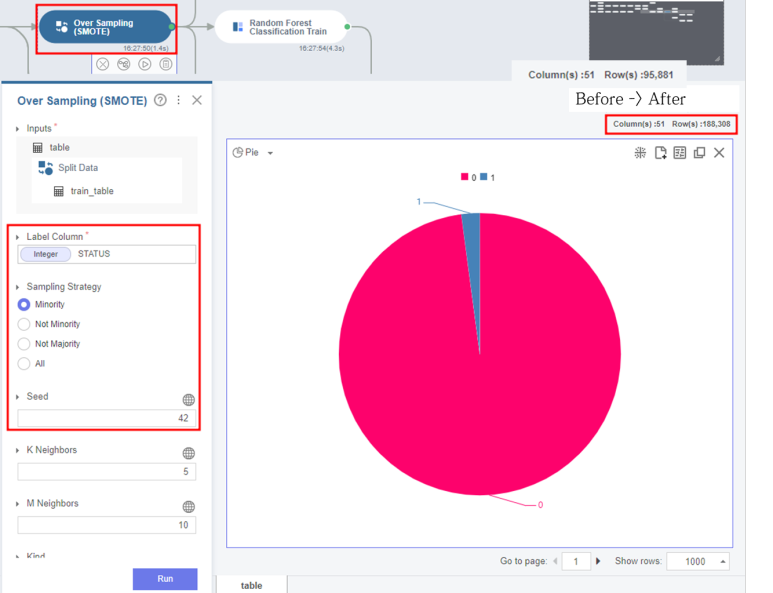
Label Column : STATUS, Sampling Strategy : Minority,
Seed : 42로 설정한 뒤 Run을 진행합니다.
샘플링된 데이터의 비율을 확인하기 위해 Chart Settings를 변경할게요!
** Pie 차트로, Color By는 STATUS로 설정합니당
하지만 Show rows을 maximum인 50,000으로 변경해도 비율은 변함이 없었어요..ㅜ
그래서 저는 Statistic Summary 함수를 사용해서 라벨 0과 1의 비율을 확인했습니다!
- 오버샘플링된 라벨 0,1의 빈도 확인_Statistic Summary 사용

Input Columns와 Group by에 STATUS를,
Target statistic에는 Number of Row를 넣어 실행합니다.
그러면 레이블 0과 1의 nrow가 같은 Table과
라벨 0과 1의 비율이 50:50으로 표현된 파이차트를 확인할 수 있어욧!
STEP2. Random Forest Classification Train (all feature /part feature)
- 모델 학습 _Random Forest Classification Train 사용
1. 전체 Columns(All feature) 사용
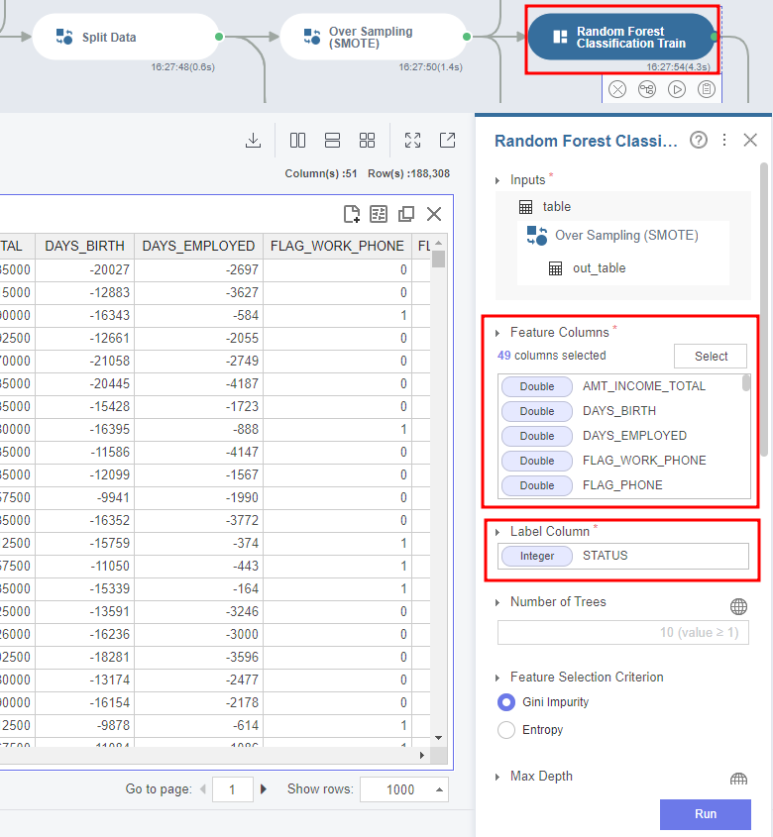
Feature Columns은 ID와 종속변수인 STATUS를 제외하고 모두 선택합니다.
그리고 Label Column은 종속변수인 STATUS를 입력해주세요!
그럼 오른쪽에 학습 결과에 대한 Report가 출력될 거예요.
그 중 Feature Importance를 살펴볼게요!
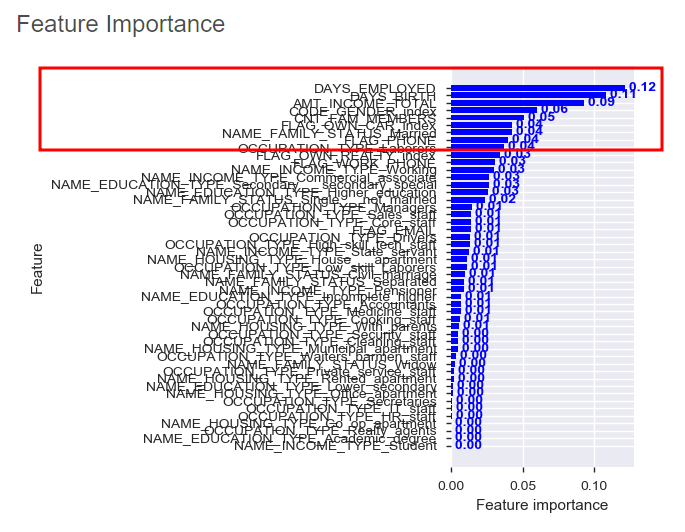
DAYS_EMPLOYED와 DAYS_BIRTH의 importance가 0.1 이상을 보이고 있다는걸 알 수 있어요!
즉, 근무 기간과 나이가 신용카드 승인 예측에 가장 영향을 많이 미치고 있다는 뜻이죵!!
그럼 이번에는 importance가 0.04 이상인 컬럼 9개를 선택한 모델을 학습한 뒤,
전체 컬럼을 대상으로 학습한 모델과 비교해보겠습니다.
일단 컬럼 9개가
근무기간, 나이, 연간 수입, 성별, 가족 수, 자가용 유무, 기혼인가?, 전화 유무, 직장인인가?
라는 것을 알아둘게요!
2. 일부 Columns(Partl feature) 사용

근무 기간과 나이 다음으로 importance가 높으면서,
동시에 0.04 이상인 컬럼 9개을 선택해서 Feature Columns에 입력해줍니다!
그리고 Label Columns도 STATUS로 입력해주었습니당

결과는 근무기간과 나이의 컬럼의 중요도가 0.2 이상으로 가장 높았고,
연간 수입>가족 수>성별> 자가용 유무/기혼인가?/전화 유무>직장인인가?
순서로 중요도가 높았습니다.
그리고 전체 컬럼 대상 모델과 일부 컬럼 대상 모델을 비교했을 때,
가족 수와 성별에 대한 중요도 우선순위가 바뀌었다는 것을 확인했습니당!
저는 신용카드가 후납의 특징을 가지고 있는 점과
신용카드 발급 신청 시, 카드사에서는 고객이 결제금액을 납부할 능력이 되는가를 평가하기 위해
고객의 사회적, 경제적 개인정보를 수집한다는 것은 알고 있었습니다.
하지만, 어떤 요인들이 신용카드 승인에 중요한 영향을 미치는지는 모르고 있었고,
이 단계를 계기로 한 회사에 근무한 기간과 고객의 나이가
신용카드 승인에 큰 영향을 미친다는 것을 알게 되었어요ㅎㅎ!!

Predict는 화살표를 2개 받는답니다!!
꼭 기억해주세요!
Train 단계에서는 'model'을 받고, Split Data에서는 'test_table'을 받아올 거예요.
그래서 받아온 모델에 test data를 적용할 겁니다!
STEP3. Random Forest Classification Predict
- 모델 예측 _Random Forest Classification Predict 사용
1. 전체 Columns(All feature) 사용
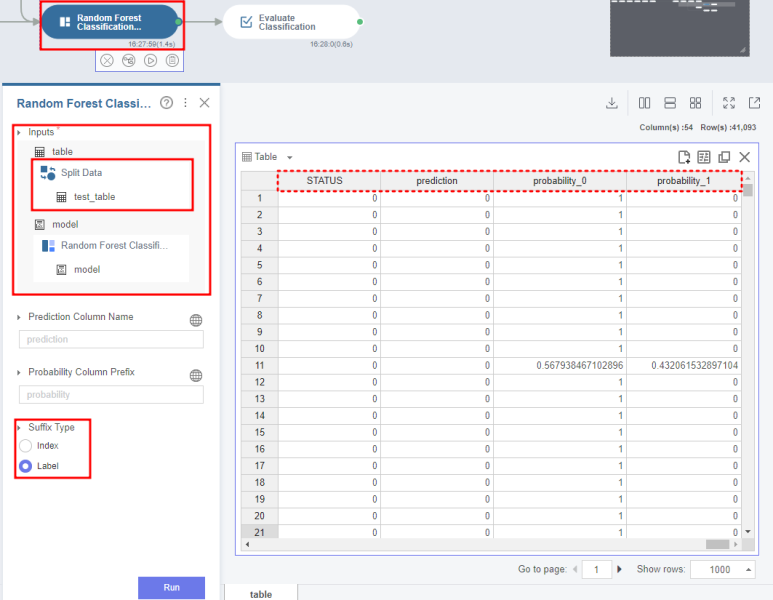
Inputs에서 table에는 디폴트 값으로 train_table이 입력되어있을거에요,
test_table로 넣어주세요!
Suffix Type는 Label로 설정해주세요.
그러면 output table의 끝부분에 prediction과 probability가 추가되어있을거에요!
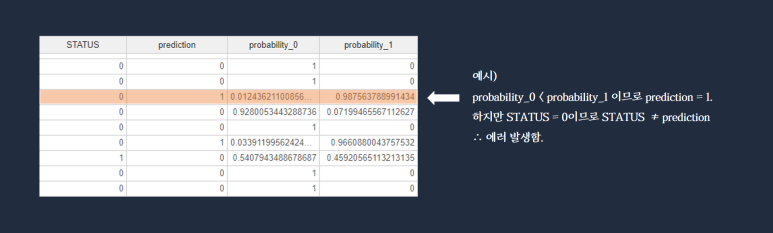
해석하는 방법은 아래의 설명과 같아요!ㅎㅎ

해석하는 예시도 자세하게 써두었어요! 참고하세욧
STATUS와 모델의 prediction이 다른 포인트를 산점도로 파악해볼게요!
Chart Type : Scatter plot, X-axis : Row index,
Y-axis : STATUS , prediction
Show rows : 100으로 설정해주면 다음과 같은 산점도를 볼 수 있어요.
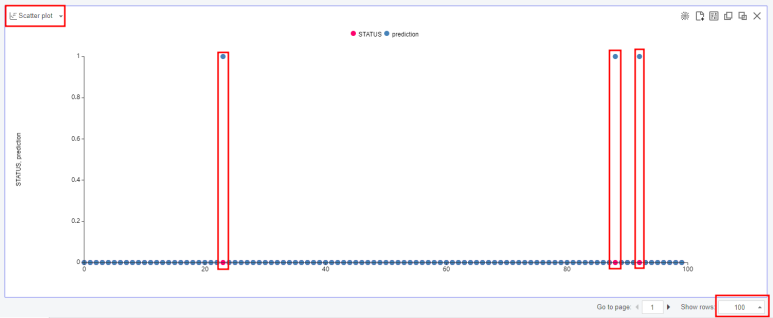
붉은 점과 파란 점이 겹치지 않는 포인트가 오류가 발생한 지점인데요,
100개의 행 중 3개밖에 오류가 발생하지 않아서 바로 성능평가를 진행했습니당!
2. 일부 Columns(Partl feature) 사용 => 생략할게요!
성능평가를 시작하기에 앞서,
이중분류 모델의 성능평가 지표인 혼동행렬에 대해 간단한 설명을 해볼게요!
Confusion Matrix(혼동행렬) :
분류모델의 학습 성능을 평가하는 지표로, 실제값과 모델의 예측값을 행렬로 배열합니다.
이진분류의 경우, 실제값과 예측값을 비교한 경우를 참과 거짓. T/F로 분류하여 다음과 같은 표로 나타내요.
|
이진분류(Binary)
|
실제
|
||
|
Positive
|
Negative
|
||
|
예측
|
Positive
|
True Positive (TP)
|
False Positive (FP)
|
|
Negative
|
False Negative (FN)
|
True Negative (TN)
|
|
TP : 실제값 참, 예측값 참
TN : 실제값 거짓, 예측값 거짓
FN : 실제값 참, 예측값 거짓
FP : 실제값 거짓, 예측값 참
그리고 이 값들을 기반으로 다양한 분류모델 평가 지표를 만들 수 있는데,
가장 많이 쓰이는 Accuracy, Precision, Recall, F-score를 계산식은 아래와 같아요!

STEP4. 성능평가
- 성능 평가 _Evaluate Classification 사용
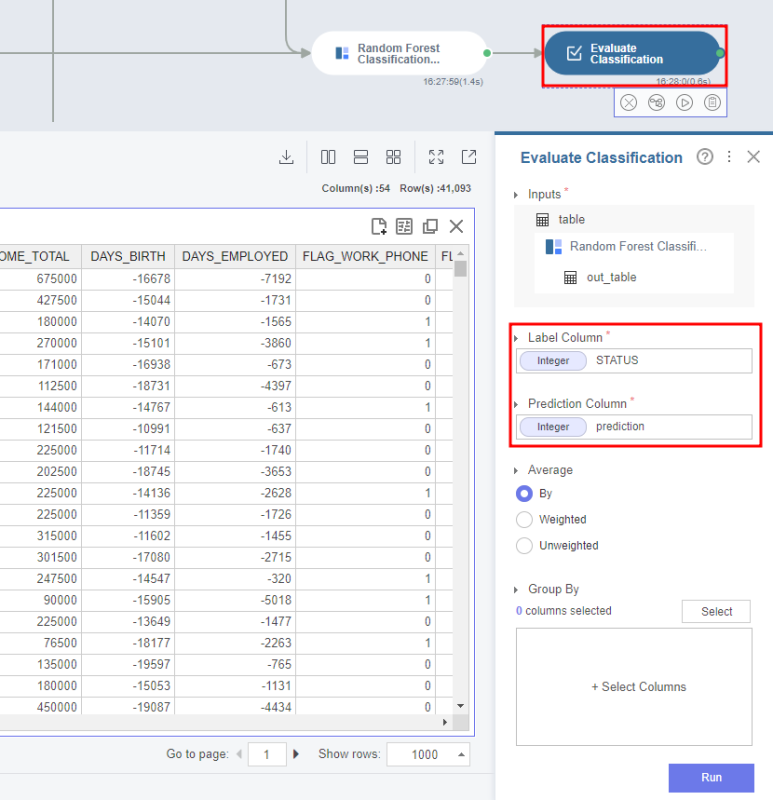
Label Column에는 기존 종속변수 데이터인 STATUS,
Prediction Column에는 모델이 예측한 prediction을 입력해서 실행해주세요!
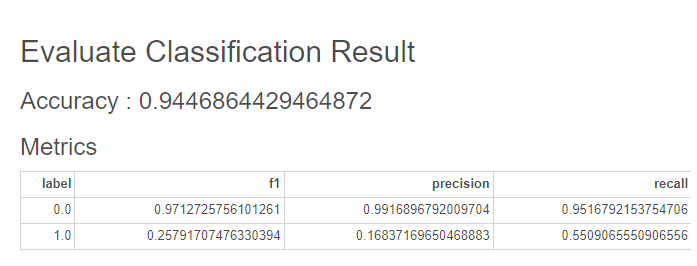
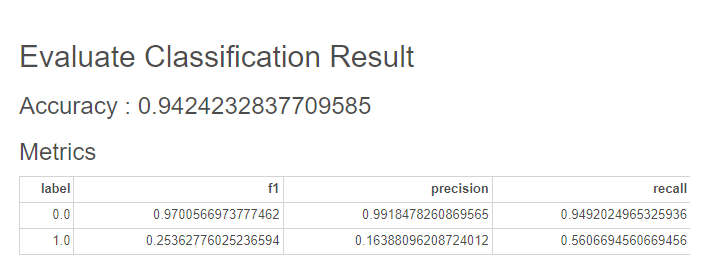
와후..
두 모델 모두 정확도가 0.94 이상이나 되는 거의 완벽에 가까운 모델이 완성됐어요!
전체 컬럼을 이용한 모델에서는
라벨이 0인 데이터에 대해 F1, 정밀도, 재현율 모두 0.95 이상의 점수를 보였고,
중요도가 높은 컬럼을 이용한 모델에서는
라벨이 0인 데이터에 대해 F1, 정밀도, 재현율 모두 0.94 이상의 점수를 보였어요.
다만 아쉬운 점은, 라벨이 1인 데이터의 점수가 두 모델 모두 낮게 나왔다는 점이네요ㅠㅠ
기회가 된다면 라벨이 1인 데이터를 대상으로
모델의 성능을 올리는 방법도 공부해보고 싶어요!
분석에 꼭 필요했던 과정들만 남겨둔 플로우는 아래 이미지와 같아요!

와아아아 드디어 3주간의 분석 프로젝트가 끝이 났어요 👏🏻👏🏻
브스를 이용한 분석 프로젝트는 저에겐 처음이었는데요,
솔직히 '신용카드 승인예측' 프로젝트를 진행하면서 처음부터 쉽지는 않았어요..ㅎㅎ
데이터 선정부터 툴 공부에 도움이 될 나름 알려진(?) 데이터를 사용해볼지,
실제 공공데이터를 사용할지 고민했고,
이 프로젝트의 첫 포스팅을 작성할 때에는
"아.. 데이터 바꿀까.." "함수 뭐 써야되는거야ㅠㅠㅠ" "하ㅠㅠ 너무 어려워"
이랬었는데, 지금 생각해보면 처음이라 그랬던 것 같아요!
저는 시각화 코드를 짜는데에 유독 시간이 오래 걸려서
데이터 전처리 후 시각화로 확인하는 작업은 생략하고 넘어가는 경우가 많았는데
브스로는 별 작업 안했는데도 바로바로 시각화로 확인할 수 있어서 너무 편하고 좋더라구요!
덕분에 시간도 아끼고 분석도 좀 더 확실해진 기분이에용ㅎㅎㅎ
이제 대회든 공모전이든
브라이틱스 스튜디오를 다룰줄 아는 사람들이랑 팀을 꾸릴 거 같아요..ㅋㅋㅋㅋ
(안써본 사람은 있어도 한번만 쓴 사람은 없을 듯 ㅇㄱㄹㅇ)
파이썬이랑 R로 돌아가면 .. 저 울지도 몰라여
브라이틱스 스튜디오를 이용한 첫번째 개인 프로젝트는 여기에서 마치겠습니다!
다음에 진행할 프로젝트들은
팀 분석 프로젝트, 팀 영상 제작 등등 다양하게 준비 중이니
열심히 기대해주세요!!
그럼 안녀어엉~!👋🏻
끝!
본 포스팅은 삼성SDS Brightics 서포터즈 3기 활동의 일환으로 작성하였습니다.